Abstraction for Offline Goal-Conditioned Reinforcement Learning
In this post, I will introduce Abstractive RL (ARL), a framework for learning abstractions in offline GCRL to improve robustness in regions where the dataset suffers from low-quality transitions. The main idea is that, as well as providing temporal abstraction, hierarchical policies enable absolute abstraction, i.e. the use of different state-representations at different levels of the hierarchy, allowing a policy to reuse experience across similar contexts of the state-space.
By introducing an inductive bias rather than an extra representational loss term, we can improve performance without introducing any additional hyperparameters.
The Problem
Offline RL is commonly formulated as a two-step procedure: first, a value function is learned, and, second, a policy is extracted from this value function. A major challenge in offline RL is extracting an optimal policy from regions of the state-space where the dataset only contains low-quality transitions. This is because, to prevent action value overestimation, model-free algorithms typically either incorporate some form of conservatism during value-learning, or regularise policy extraction towards the dataset distribution using behaviour cloning.
Recent Rejection-Sampling-based methods take this to the extreme: by learning the dataset-generating policy using behaviour cloning, and then, at deployment, sampling actions from this policy and choosing those with the highest value, the deployed policy will never take higher-quality actions than those contained within the dataset.
The Idea: Abstractive RL
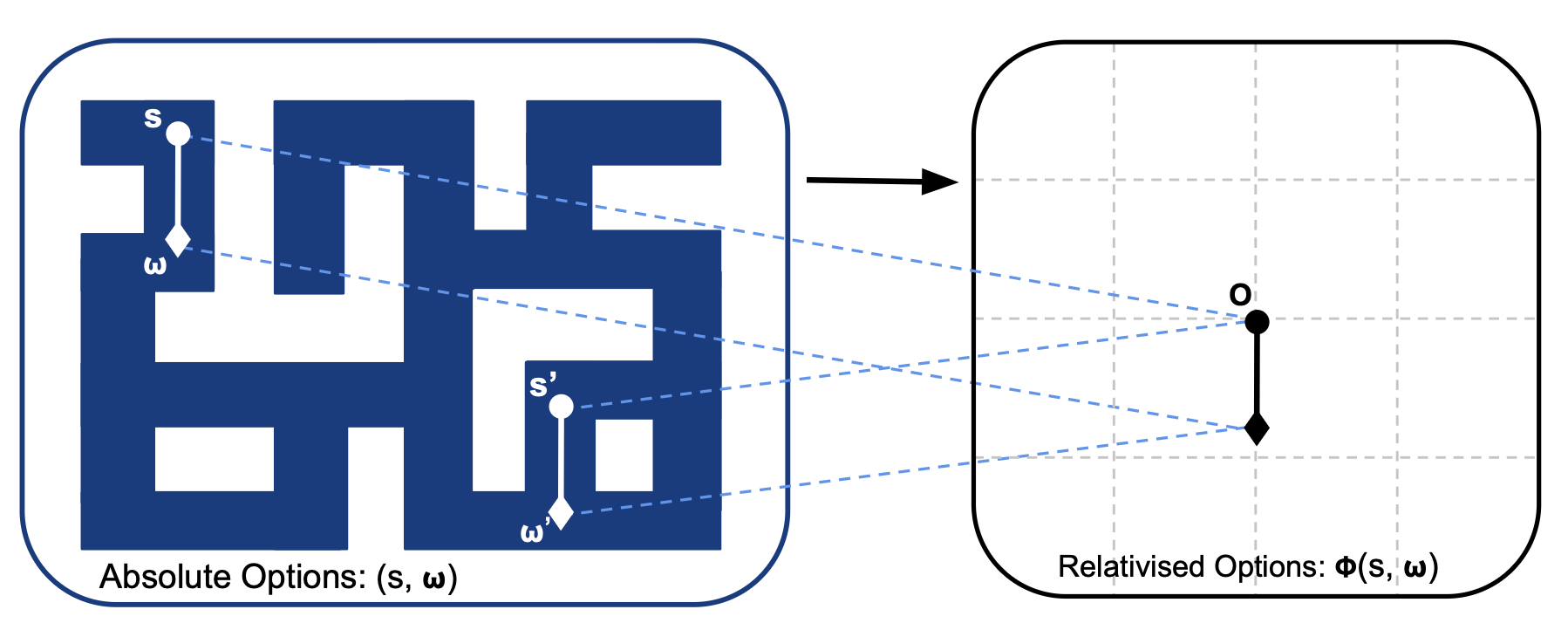
In principle, our aim is to learn abstractions that enable the reuse of experience across similar contexts. By learning options that group together state-waypoint pairs which, under an optimal policy, induce similar action sequences, options would be relative rather than anchored to an absolute frame of reference. This would naturally induce two hierarchical notions of similarity: a high-level similarity, where similar state-goal pairs induce similar options, and a low-level similarity, where similar state-option pairs induce similar immediate actions.
Our aim would be to learn high-level embeddings $\phi_h(s,g)$ and low-level embeddings $\phi_l(s,\omega)$ that abstract away information irrelevant to their respective levels: $$ \pi(a \mid s,g) = \pi_l(a \mid \phi_l(s, \omega)) \quad \text{where} \quad \omega \sim \pi_h(\cdot \mid \phi_h(s,g)). $$
The Implementation
We now use the above framework to guide algorithmic decision making.
- First, allowing the high-level and low-level decision processes to operate on different representations and at different temporal abstractions (discount factors), requires two value functions.
- Second, options should be learned via action similarity rather than, for example, value-similarity.
Abstractive RL Implicitly Learning Relativised Options (ARLi)
We make the most minimal amendment to Hierarchical Implicity Q-Learning (HIQL) to comply with the ARL framework. We learn two value functions: one for the high-level policy and one for the low-level policy. Following HIQL, the option space is bounded to a hypersphere to introduce geometric regularisation, rather than simply learning a distinct embedding for every possible state-waypoint pair. However, rather than learning option representations jointly with the value function, we learn option representations with the low-level policy. Intuitively, we want to push together state-waypoint pairs that require similar low-level actions rather than state-waypoint pairs with similar values.
| Task | Size | Dim. | HIQL | ARLi |
|---|---|---|---|---|
| pointmaze-giant-navigate-v0 | 1M | 2 | 55±11 | 48±8 |
| pointmaze-giant-stitch-v0 | 1M | 2 | 0±0 | 0±0 |
| antmaze-giant-navigate-v0 | 1M | 29 | 38±3 | 48±3 |
| antmaze-giant-stitch-v0 | 1M | 29 | 7±7 | 32±7 |
| antmaze-teleport-stitch-v0 | 1M | 29 | 29±4 | 36±5 |
| humanoidmaze-giant-navigate-v0 | 4M | 69 | 22±11 | 49±6 |
| humanoidmaze-giant-stitch-v0 | 4M | 69 | 4±3 | 13±2 |
| cube-double-play-v0 | 1M | 37 | 2±0 | 53±2 |
| cube-triple-play-v0 | 3M | 46 | 7±3 | 14±2 |
| cube-quadruple-play-v0 | 5M | 55 | 0±0 | 1±0 |
| puzzle-3x3-play-v0 | 1M | 55 | 27±8 | 86±14 |
| puzzle-4x4-play-v0 | 1M | 83 | 49±27 | 78±11 |
| puzzle-4x5-play-v0 | 3M | 99 | 17±3 | 18±3 |
| puzzle-4x6-play-v0 | 5M | 115 | 0±0 | 14±7 |
| scene-play-v0 | 1M | 40 | 12±3 | 24±3 |
The results are promising! Without any hyperparameter tuning (we simply inherit those tuned for HIQL), we achieve non-trivial performance in many of the higher-dimensional OGBench environments.
Abstractive RL Explicitly Imposing Translation Invariance (ARLe)
At a much more extreme level, we now impose translation invariance on the low-level
value function
to explicitly enforce learning from similar contexts across the state-space.
We use relativised states, which we define as $v = g_s - s$, where $s$ is the
current state
and $g_s$ a waypoint to the goal, and explicit relativised options to
encourage abstraction from the absolute frame of reference. We do still condition
the low-level policy on the absolute state, however, to enable the policy to satisfy local
constraints.
Notably, ARLe outperforms ARLi in two out of the four sparsest datasets:
| Task | Size | Dim. | ARLi | ARLe |
|---|---|---|---|---|
| pointmaze-giant-navigate-v0 | 1M | 2 | 48±8 | 16±2 |
| pointmaze-giant-stitch-v0 | 1M | 2 | 0±0 | 0±0 |
| antmaze-giant-navigate-v0 | 1M | 29 | 48±3 | 42±4 |
| antmaze-giant-stitch-v0 | 1M | 29 | 32±7 | 21±1 |
| antmaze-teleport-stitch-v0 | 1M | 29 | 36±5 | 41±4 |
| humanoidmaze-giant-navigate-v0 | 4M | 69 | 49±6 | 38±4 |
| humanoidmaze-giant-stitch-v0 | 4M | 69 | 13±2 | 10±3 |
| cube-double-play-v0 | 1M | 37 | 53±2 | 67±3 |
| cube-triple-play-v0 | 3M | 46 | 14±2 | 15±3 |
| cube-quadruple-play-v0 | 5M | 55 | 1±0 | 0±0 |
| puzzle-3x3-play-v0 | 1M | 55 | 86±14 | 44±25 |
| puzzle-4x4-play-v0 | 1M | 83 | 78±11 | 88±6 |
| puzzle-4x5-play-v0 | 3M | 99 | 18±3 | 14±7 |
| puzzle-4x6-play-v0 | 5M | 115 | 14±7 | 9±9 |
| scene-play-v0 | 1M | 40 | 24±3 | 21±3 |
The results are less impressive than ARLi (this rigid enforcement is not ideal in practice and will not scale: the representation is too lossy!), but what is the potential?
It is a proof of concept:
Let's Answer Some Potential Questions...
Why do we not tune hyperparameters for ARL?
Offline RL typically requires significant online tuning, which is
expensive and would be
unscalable for training a billion-parameter general-purpose agent. Scaling offline RL should be
robust to hyperparameters, which is why our work focuses on inductive
biases rather than
representational losses that introduce additional hyperparameters.
Why does ARL still perform poorly in certain tasks?
There are many confounding factors! Some examples: poor high-level value learning and a lack of
gradient in long horizon tasks; the high-level policy being unimodal rather than multimodal; not
training for enough gradient steps for large dataset sizes; not learning goal representations for
the high-level policy.
The aforementioned issues could be mitigated by combining ARL with value horizon reduction methods
such as TD-$n$ or
Transitive
RL, learning a Flow Policy rather than a Gaussian (especially for the high-level policy),
training for more steps (we run all experiments for 1M), and using representation learning for the
high-level decision process.
What environments does ARL have most impact in?
Both of our ARL-guided algorithms exhibit positive improvement trends over our benchmark algorithms
with increasing dataset sparsity, which would make sense; relativised options and experience reuse
become increasingly important as sparsity increases.
What's Next?
This work just acts as a proof of concept that relativised options and inductive biases can improve generalisation in offline GCRL.
Now: can we impose more flexible inductive biases? Or leverage action chunking to learn relativised options over action sequences?
Acknowledgements
Thank you to Seohong Park, whose work inspired many of these ideas.